
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 카카오코테
- 카카오 코딩테스트
- Cannot connect to the Docker daemon at unix
- 파이썬
- 부캠
- 도커연결오류
- 파이썬 재귀함수
- 부스트캠프
- 파이썬 카카오코딩테스트
- 코딩테스트
- 파이썬 프로그래머스
- 프로그래머스 레벨2
- 부스트캠프AITech
- 프로그래머스
- 프로그래머스 파이썬
- 양과늑대
- 부스트캠프 회고
- 도커오류
- 프로그래머스LEVEL1
- 카카오 파이썬
- 프로그래머스 레벨1
- 프로그래머스 양과늑대
- 프레임워크란?
- 라이브러리란?
- docker시작하기
- 프로그래머스 레벨3
- 파이썬 양과늑대
- level1
- 네이버 부스트캠프
- 카카오코딩테스트
- Today
- Total
코린이의 공부일기
semantic segmentation 대회에서 사용하는 방법 본문
- Semantic segmentation 에서 필살기를 살펴보고 대회에서 사용하는 기법들을 살펴보자
1. 5-Fold Ensemble

-5 fold cross validation을 통해 만들어진 5개의 모델을 ensemble하는 방법
2. Epoch Ensemble

checkpoint을 지정해주며 비슷한 값끼리 활용해 ensemble하는 방법도 있다.
3.SWA(Stochastic Weight Averaging)

각 step마다 weight을 업데이트 시키는 SGD와 달리 일정 주기마다 weight를 평균 내는방법
-Train loss에서는 SWA가 더 높을 수 있지만 Test error에서는 SGD가 높다 -> 일반화가 더 잘 되어있는 것

-Warm up period - Epoch가 진행함에 따라서 초반75%는 원래 LR로 진행
나머지 25 %는 SWA을 진행
-> Average DNN weights
-Update BN -> SWA을 통해 만든 평균된 weight의 경우는 기존 train data의 Batchnorm의 통계치와는 다름.
-> 고정해주기위해서 Batchnorm자체를 update시켜주는 것

4.Seed Ensemble

-장점 : Private dataset에 대해 조금 더 일반성이 높아질 수 있음.
5. Resize Ensemble

Input 이미지의 size을 다르게 학습하는 Ensemble하는 방법
-다양한 Object size에 대해 일반성을 높일 수 있음.
6. TTA(Test time augmentation)

inference할 때, image에 augmentation을 적용하는 것
-> 성능향상에 많은 영향을 끼침
-같은 모델을 활용하여 inference을 진행하여 prediction 1~4까지 평균을 내 최종결과를 생성하는 기법
* segmentation은 좌표 값들도 나오기 때문에 원본 이미지로 rotation해줘야함

학습 때와 다른 size의 input이미지를 이용해 Test(Inference)하는 방법
-> semantic segmentation에 성능향상에 많은 영향을 줌,
-TTA Library - ttach


여러 Transform을 선택해 각각의 TTA을 조합해 여러가지 TTACase을 설정해 TTA을 수행한다.
+Lose , Optimizer ensemble
7. Pseudo Labeling
가짜 label을 부여해 학습해 참여시키는 방법

+추가 (Classification 결과를 활용하는 방법)
Encoder Head 마지막단에 Classification head을 달아서 같이 활용(Unet3+ 에서 활용)

촤근 딥러닝 이미지 대회 Trend

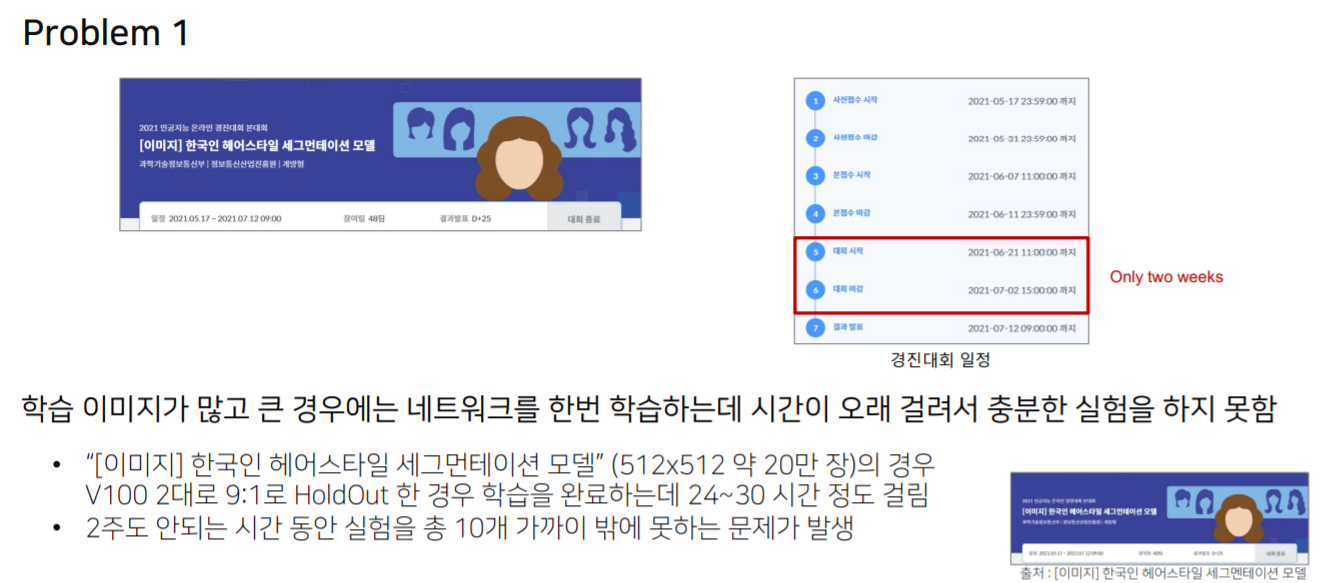
-> SOlUTION
- FP16(부동 소수점 변경)
-실험 간소화
-가벼운 모델
Solution1 . Mixed Precision Training of Deep Neural Networks
-속도를 높이기 위한 FP16 연산과 정확도를 유지하기 위한 FP32 연산을 섞어서 학습하는 방법->memory효율성 늘어남

-Batch 사이즈를 키울 수 있음

Solution2 . 가벼운 상황으로 실험
-일부 데이터 사용
-단, LB와 Validation Score 간의 어느 정도 상관관계가 있어야함
-K-Fold 보다는 단일 Fold로 검증

-[짧은머리-남성],[긴머리-여성],[단발머리-여성],[긴머리-여성]등의 다양한 헤어스타일에 대해 image을 샘플링하거나 또는 동일한 사람에 대해 샘플링하여 sub data 을 만들어 여러 augmentation, model을 실험해 좋은 기법을 찾아
전체 데이터를 학습.
Solution 3. 가벼운 모델로 실험
가벼운모델로 augmentation, Optimizer 등 어떤 기법들이 적합한지 체크하고 무거운 모델로 돌려 최종 성능 확인.

Solution - Input과 Ground Truth을 Resize하여 Prediction을 만들고 다시 원본 사이즈로 interpolation시켜 제출
-> 그치만 문제점이 있음

Solution . Sliding Window(Overlapping)
-image size가 크기 때문에 window단위로 잘라서 모델의 학습과 inference하는 기법
->중요한 부분 : window size, stride size

-Window size가 작다면, 객체의 국소적인 정보가 들어오기 때문에 prediction향상에 영향을 많이 미치지 못함.
-Window size가 크다면 , object가 거의 잡혀 성

stride도 작다면 겹치는영역이 많아지며 input image수도 많아지고 학습하는 양이 많아지며 다양한 정보가 많이 추출될 수 있다.

+
새로운 object형태도 추출할 수 있다.
단점 : 일반적으로 겹치제 자르면 다양한 정보를 얻을 수 있지만, 학습데이터의 양이 많이 늘어나게 될 수 있으며 중복되는 정보가 많아 학습데이터가 늘어나는 양에 비해 성능의 차이는 적고 학습 속도가 오래 걸리는 문제가 발생한다.
+추가 TIP
1.일반적으로 Train 에 사용된 sliding window의 크기와 inference에 사용되는 sliding wondow의 크기가 동일해야 한다고 생각하는 경우가 많지만 , input image와 inference image의 크기가 같을 필요는 없음

2. Sliding window을 적용하면 유의미하지 않은 영역들이 잡히는 경우가 많기 때문에
Prediction 후, object가 제대로 나온 center부분만 crop

3.전체 이미지에서의 유의미하지 않은 영역들을 위해 Segmentation/ object detection을 통해 object부분을 crop

Output image 확인
- 큰 object와 작은 object을 잘 예측할 수 있는지
-특정 class에 대해 잘 맞추는지
Label에 Noise가 있는 경우 TIP

-boundary 부분이 정확히 label되어 있지 않은 경우

-label이 올바르게 되지 않은 경우
(plastic bag와 plastic이 모두 존재하지만 모두 plastic bag으로 label)
[Label Noise가 발생하는 원인]
-일반적으로 segmentation에서의 annotation task는 픽셀단위로 이루어지기 때문에 어려움이 존재
-annotation guide가 주어지지더라도 사람마다 기준이 다름
-사람이기 때문에 annotation실수도 존재
Solution . 1 Label Smoothing

Solution . 2 Pseudo-labeling

-전체 dataset에 각각에 대해 miou을 계산하여 오름차순으로 나열해본다면,
아주 낮은 miou을 갖는 data는 noised GT을 예상
Solution
->pseudo labeling
->delete
'BOOST CAMP_정리' 카테고리의 다른 글
| AutoML의 이론 (0) | 2021.11.23 |
|---|---|
| [Boost Camp] 7강 _ 성능 평가 방식 (0) | 2021.11.11 |
| [Boost Camp]MMDetection & Detectron2 (0) | 2021.09.29 |
| [Boost camp] 2 Stage Detectors (0) | 2021.09.28 |
| [Boost Camp] 09_24 특강 (0) | 2021.09.24 |



