
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- Cannot connect to the Docker daemon at unix
- 라이브러리란?
- 부스트캠프 회고
- 카카오코테
- 프로그래머스LEVEL1
- 파이썬 카카오코딩테스트
- 파이썬 프로그래머스
- 프로그래머스 양과늑대
- 프레임워크란?
- 파이썬
- 코딩테스트
- 프로그래머스
- 도커오류
- level1
- 네이버 부스트캠프
- 부스트캠프
- 카카오 코딩테스트
- 파이썬 재귀함수
- 프로그래머스 파이썬
- 프로그래머스 레벨3
- 카카오코딩테스트
- docker시작하기
- 카카오 파이썬
- 부캠
- 프로그래머스 레벨2
- 부스트캠프AITech
- 프로그래머스 레벨1
- 양과늑대
- 파이썬 양과늑대
- 도커연결오류
- Today
- Total
코린이의 공부일기
모델 최적화 1강 ) 최적화 소개 본문
스마트워치나 스마트폰에 그 밖에 IoT Device에 머신러닝어플리케이션이 올라가서 inference을 수행경우가 많이 생김
1. On device AI

Vision이나 Natural Language의 기능이 On device에서 많이 사용되고 있다.
On device 의 한계점
-파워사용량
-RAM memory
-저장공간 제약
-Computing 파워의 제약
2. AI on cloud(or server)
-배터리, 저장공간, 연산능력의 제약을 줄어드나 latency와 throughput의 제약이 존재
latency : 요청에대해서 소요되는 시간
throughput :단위시간 당 처리가능한 요청 수
-같은 자원으로 더 적은 latency와 더 큰 throughput이 가능하다면?
-> 경량화가 무조건 필요하다
3. Computation as a key component of AI progress

-2012년 이후 큰 AI 모델 학습에 들어가는 연산은 3,4개월마다 두배로 증가해옴
경령화의 목적
- 모델 연구와는 별개로, 산업에 적용되기 위해 거쳐야하는 과정
- 요구조건(하드웨어 종류, latency 제한, 요구 throughput ,성능) 들 간의 trade-off을 고려해 모델 경량화/ 최적화를 수행
경량화 , 최적화의 대표적인 종류
-네트워크 구조 관점
1. Efficient Architeture Design (+AutoML; Neural Architecture Search(NAS))
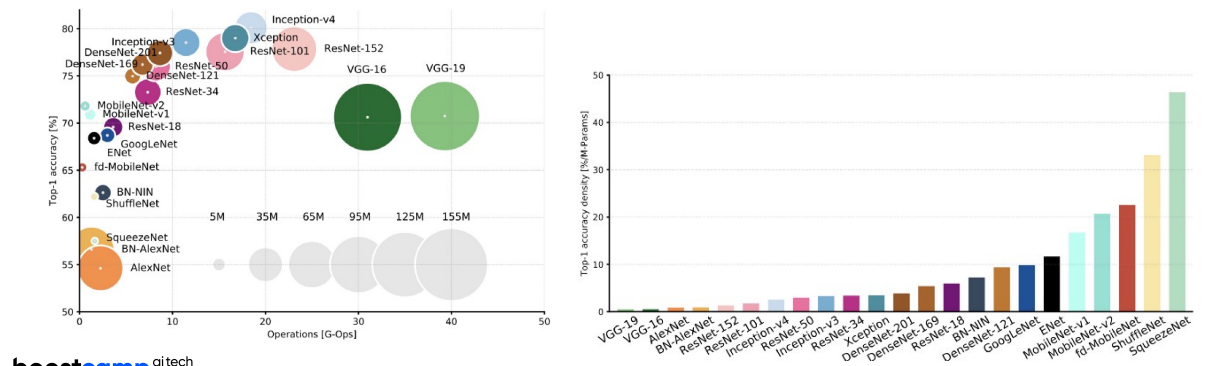
-모듈 블럭들 (VGG, Efficient net등) 작은 모델을 만드는 것을 경량화라고 볼 수 있다.
2. Network Pruning 네트워크의 중요도가 낮은 파라미터들을 제거해보는 접근
3. Knowledge Distillation 학습된 큰 규모의 Teacher network을 student network에 전달하는 것
4. Matrix/ Tensor Decomposition 학습된 network에 대해서 convolution Tensor을 더 작은 단위의 Tensor의 곱과 합으로 변경해주는 것 -> 연산량이 줄어듬
-Hardware 관점
5. Network Quantization - 일반적으로 학습된 네트워크의 float32로 되어있는데 비트수가 16개 or 8개의 더 작은 데이터타입으로 매핑하는 것
6. Network Compiling -inference을 좀 더 효율적으로 할 수 있도록 network자체를 컴파일 하는 작업
1. Efficient architecture design *
- 매년 쏟아져 나오는 블록 모듈들
- 각 모듈 블록마다의 특성이 다름(성능, 파라미터 수, 연산 횟수,...)
- 경량화에 특화된 모듈들을 디자인하는 것
Software 1.0 : 사람이 짜는 모듈
Software 2.0: 알고리즘이 찾는 모듈(Auto ML, NAS)
모델을 찾는 네트워크 (controller)
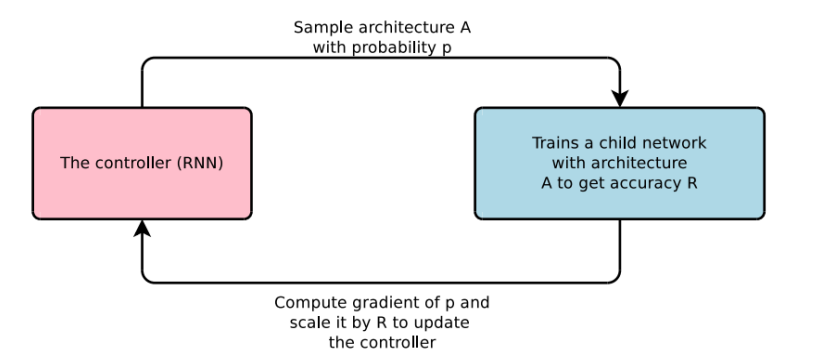
-iterative하게 계산 ->사람의 직관보다 상회하는 성능의 모듈들을 찾아낼 수 있음.
(어떤의미로 연결되는지 사람이 직관적으로 이해하기는 힘듬)
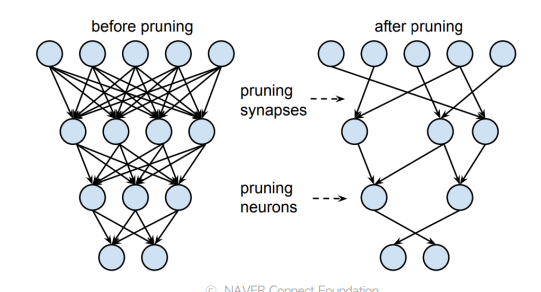
2. Network Pruning :찾은 모델 줄이기
- 중요도가 낮은 파라미터를 제거하는 것
- 좋은 중요도를 정의, 찾는 것이 주요 연구 토피 중 하나
(eg. L2 norm이 크면 loss gradient크면 등등)
- 크게 structured/ unstructured pruning으로 나누어짐
Network pruning :structured pruning
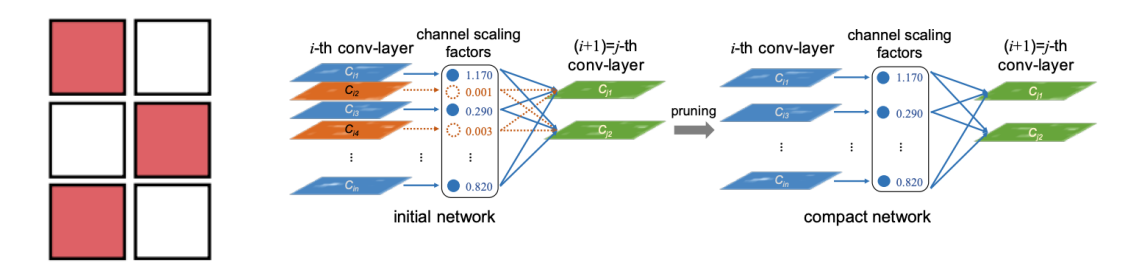
- 파라미터를 그룹 단위로 pruning하는 기법들을 총칭 (channel/ filter , layer등)
- Dense computation에 최적화된 소프트웨어 또는 하드웨어 적합한 기법
channel scaling factors -> 파라미터의 중요도
왼쪽 예시 ) filter단위로 pruning진행
Network Pruning: Unstructured pruning
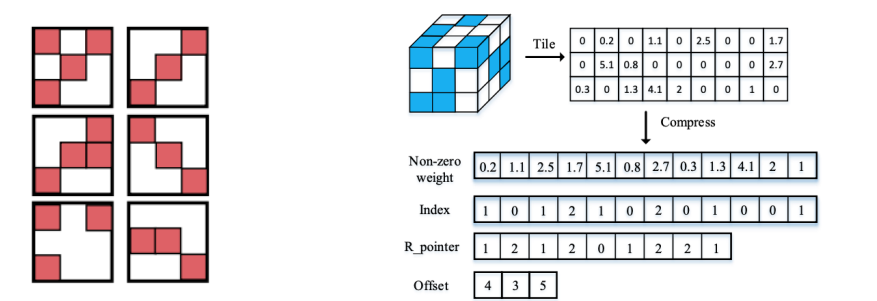
-파라미터 각각 독립적으로 pruning하는 기법
-pruning을 수행할 수록 네트워크 내부의 행렬이 점차 sparse해짐
-structured pruning과 달리 sparse computation에 최적화된 소프트웨어 또는 하드웨어에 적합한 기법
3.Knowledge distillation **
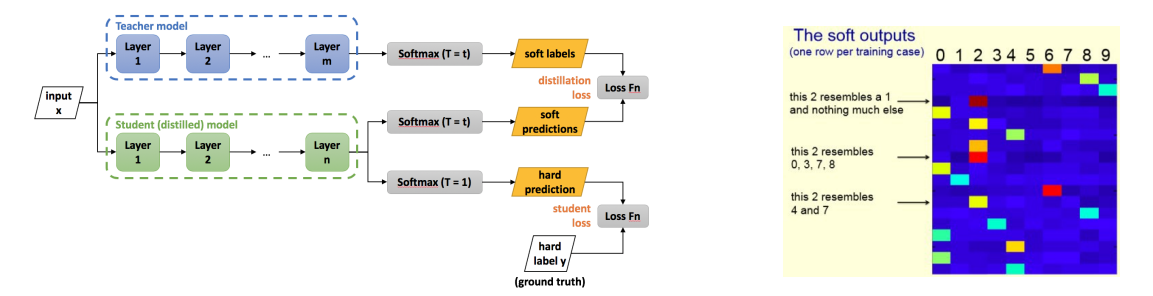
-학습된 큰 네트워크를 작은 네트워크의 학습 보조로 사용하는 방법
-Soft target(soft output)에는 ground truth보다 더 많은 정보를 담고 있음(특정 상황에서 레이블 간의 유사도 등등)
1)Student network와 ground truth label의 cross -entropy
2) teacher network와 student network의 inference 결과에 대한 KLD loss로 구성
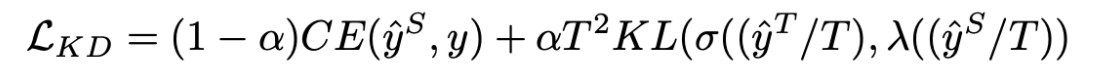
T 는 large teacher network의 출력을 smoothing(soften)하는 역할을 한다
α는 두 loss의 균형을 조절하는 파라미터이다.
4. matrix/Tensor decomposition
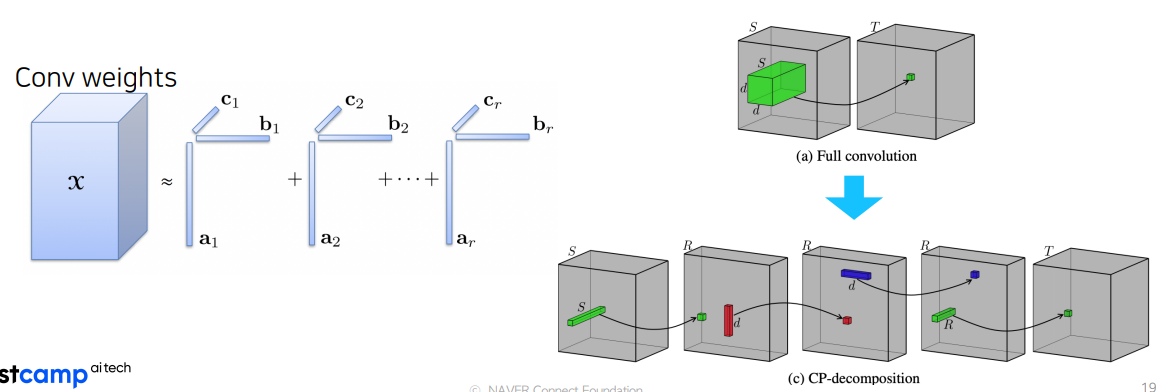
-하나의 Tensor을 작은 Tensor들의 operation들의 조합(합, 곱)으로 표현하는 것
-Cp decomposition: rank 1 vector들의 oute product의 합으로 tensor을 approximation
-CP-decomposition의 연산결과와 Full convolution의 결과가 비슷하게 나온다.
하드웨어 관점의 경량화
5.Network Quantization

-일반적인 float32 데이터타입의 Network의 연산과정을 그보다 작은 크기의 데이터 타입 (e.g float16, int8,..)으로 변환해 연산을 수행
-> Quantization Error가 있음에도 불구하고 어느정도 Robust하게 작동한다 그래서 많이 사용되고 있다.
-사이즈 : 감소
-성능 : 약간 하락
속도: hardware지원 여부 및 사용 라이브러리에 따라 다름
6. Network Compiling
- 학습이 완료된 network을 deloy하려는 target hardware에서 inference가 가능하도록 compile하는 것
- 사실상 속도에 가장 큰 영향을 미치는 기법
(e.g TensorRT(NVIDIA), Tflite(Tensorflow) , TVM(apache) ...
- 각 compile library마다 성능차이가 발생
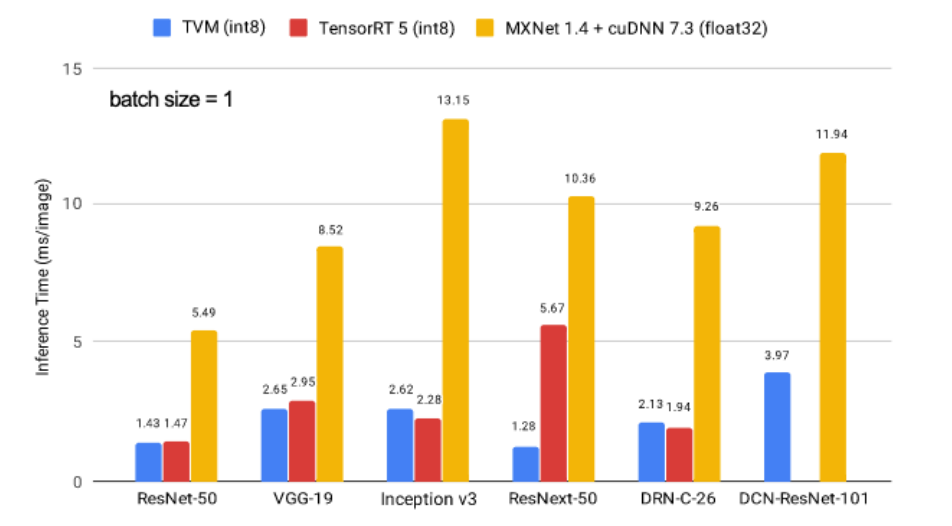
-Layer fusion
compile과정에서 layer fusion등의 최적화가 수행됨
예를들어 tensorflow같은 경우 200개의 rule이 정의되어있음
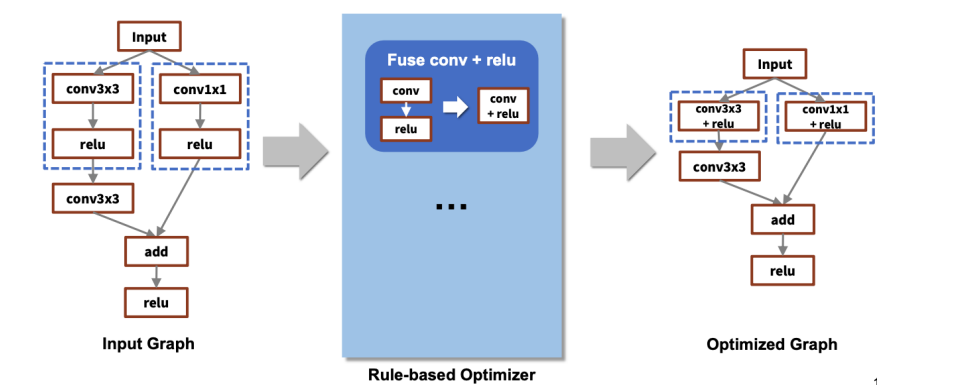
-문제점
1. Framework와 hardware backends 사이의 수많은 조합->HW마다 지원되는 core, unit수, instruction set , 가속 라이브러리 등이 다르다
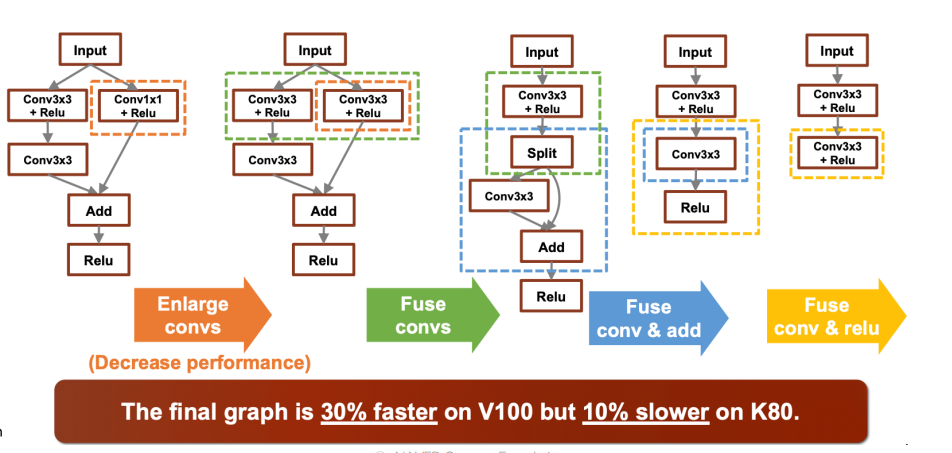
-성능에 대한 파급력은 굉장히 좋지만 지원되는 하드웨어나 프레임워크들을 고려해야하는 문제점이 있다.

대회소개 & FLOPs
경량화 평가하기?
어떤것에 포커스를 둬야할까?
모델크기 / 속도/ 연산횟수
이번대회는 직접적으로 inference속도를 대회 기준으로 결정
Task는 비교적 익숙한 이미지 분류로 설정
-> 성능이 좋으면서 inference속도가 가장 빠른 모델 찾기

추천 논문 : ShuffleNetv2 , 속도에 영향을 주는 요소에 대한 insight
Dataset- LEVEL2 CV P-stage Object detection에서 사용되는 데이터와 동일
-> 경량화에 집중
- '경량화'의 취지에 더 집중하기 위해 Bonding box을 crop해 classification task로 변경