
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 카카오 파이썬
- 네이버 부스트캠프
- 도커오류
- 부스트캠프 회고
- level1
- 양과늑대
- 프로그래머스 양과늑대
- docker시작하기
- 파이썬 재귀함수
- 프로그래머스
- 카카오코테
- 부캠
- 도커연결오류
- 프레임워크란?
- 프로그래머스LEVEL1
- 프로그래머스 파이썬
- 카카오 코딩테스트
- 라이브러리란?
- 파이썬
- 카카오코딩테스트
- 프로그래머스 레벨1
- 프로그래머스 레벨2
- 부스트캠프AITech
- 파이썬 카카오코딩테스트
- 파이썬 양과늑대
- 부스트캠프
- 파이썬 프로그래머스
- 프로그래머스 레벨3
- 코딩테스트
- Cannot connect to the Docker daemon at unix
- Today
- Total
코린이의 공부일기
Quantization 이론 본문
Quantization 이란?
* 좋은 해상도를 가지는 input value을 낮은 해상도를 가지도록 output value로 mapping하는 것
-Mapping input values from a large set to output values in a smaller set

original에서의 -1값이 -> quantization에서는 -0.25로 mapping
-1~+1 -> -0.25~0.25로 구간 간격이 절반이 됨.
-introduction

-2015년에 나온 Inception V3 model 첫번 째 Conv layer weight 분포
-256개의 bin을 가지는 histogram으로 plot
-Bit encoding
기존의 32bit float 값을 8 bit int(256개의 bin)으로 fixed point mapping(encoding)하면 어떨까?
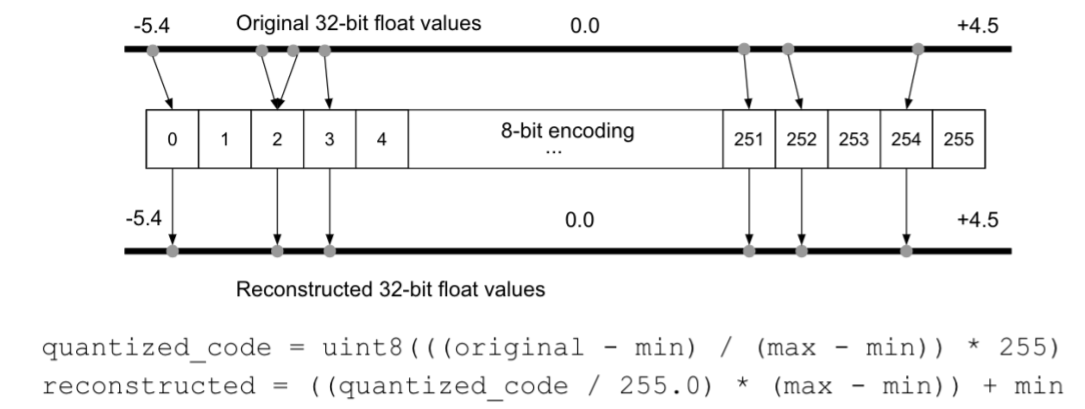
->결과적으로 원하는 결과를 얻을 수 있었음.
AlexNet -240MB을 62MB로 줄일 수 있었다.
Quantization의 이점
모델 사이즈를 줄여주는 것 말고 그 밖에는 ?
1. 일반적인 필터 연산 과정 : input * weight (+bias) -> activation

2. 하드웨어에서는 MAC(Multiply-Accumulate) unit을 통해서 해당 연산을 수행
각 픽셀에서 누적해서 weight을 곱하고 더하는 작업을 축척하는 방식
->이 방식은 에너지 소비관점에서도 되게 유리하다.

-외부 메모리 접근의 높은 Cost을 가지지만, 한번에 읽어오는 크기도 늘어나면서( X4 bandwidth) , 효율은 더 좋아짐
-NN에서의 Quantization
기존의 high precision(일반적으로 fp32) Neural network의 weight와 activation을 더 적은 bit(low precision)으로 변환하는 것
Fixed point (고정 소수점)
- 수 표현의 방법: 1) Fixed point(32 bit)
1. 등간격으로 수를 표현
2. 항상 동일한 해상도 가짐

실수를 표현하는 방식 - 소수부의 자릿수를 정하고, 고정된 자릿수의 소수를 표현하는 것
->But Fixed point의 단점은 정수부와 소수부의 자릿수가 크지 않으므로, 표현할 수 있는 값의 범위가 매우 적다는 단점이 있다.
정수를 표현하는 bit을 늘리면 큰 숫자의 표현은 가능하지만, 정밀한 숫자의 표현은 힘들다
또한 소수를 표현하는 bit을 늘린다면 정밀한 숫자를 표현할 수 있지만 큰 숫자의 표현은 힘들다
그래서 이 문제의 해결을 위해 소수점을 고정하지 않고, 소수를 표현할 수 있는 부동소수점 (floating point)을 사용하고 있다.
Floating Point(부동 소수점)
하나의 실수를 부호(sign), 가수(mantissa), 지수(exponent)로 나누어 표현하는 방식이다
부호- 전체 수가 양수(0) OR 음수(1)
지수 - 2의 지수
가수 - 소수 이하를 표시
부동 소수점의 표현 범위에 따라 단점도/ 배정도로 나뉨
단정도 : 32bit float형 실수를 표준에 방식으로 표현
배정도 : 64bit double형 실수는 지수부가 11bit, 가수부가 52 bit로 바뀐다.
예를들어 32bit

point) 지수도 양수와 음수를 구별해서 나타낼 수 있어야함.
양의 지수와 음의지수를 표현하기 위해서는 바이어스 (bias)을 사용한다. 단정도는 127 배정도는 1023을 사용
ex) 2^10 -> 지수 10에 바이어스 127을 더한 137을 2진수로 바꾸어 지수에 저장
2^-10 -> 지수 -10에 127을 더한 117을 2진수로 바꾸어 지수에 저장한다.
문제 ) 8.625를 단정도( single precision)방식으로 표현하라

Quantization mapping
-floating 32 -> int8 -> floating 32 process 을 살펴보자
High precision -> Low precision mapping

*quantized_code - xq
*reconstructed - x
* 주의할 점, zero padding 에서 0 값이 Quantization을 할 때, 0값으로 mapping이 되지 않는다면 성능저하가 일어날 수 있다.
그렇기 때문에 NN에서는 floating point 0.0이 Quantization후에도 0을 유지하여야한다.
