
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 라이브러리란?
- 파이썬 프로그래머스
- 카카오 코딩테스트
- 부스트캠프AITech
- 부스트캠프
- 프로그래머스
- 도커연결오류
- 카카오코테
- docker시작하기
- 도커오류
- 파이썬
- 프로그래머스 파이썬
- 네이버 부스트캠프
- 카카오코딩테스트
- 양과늑대
- 프로그래머스LEVEL1
- 프레임워크란?
- 부스트캠프 회고
- 프로그래머스 레벨3
- 파이썬 재귀함수
- 파이썬 카카오코딩테스트
- Cannot connect to the Docker daemon at unix
- 프로그래머스 레벨1
- 카카오 파이썬
- 프로그래머스 레벨2
- 코딩테스트
- 파이썬 양과늑대
- 부캠
- level1
- 프로그래머스 양과늑대
- Today
- Total
코린이의 공부일기
[Boost Camp] Week 4 Day 2. P.stage( Dataset ) 본문
Dataset
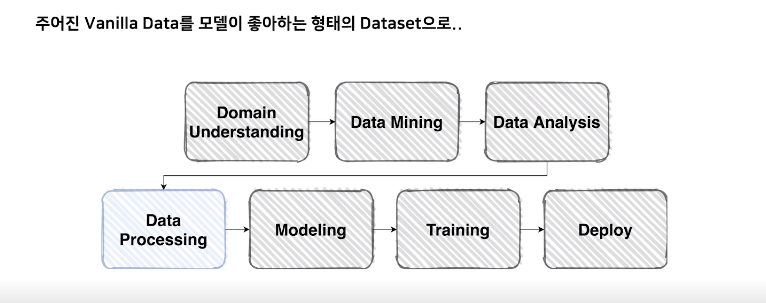
Data Processing
내가 원하는 데이터의 형태로 가져오는 것
=문제를 풀기 위해 데이터의 형태를 파악하고 전처리 작업하는 것
Pre-processing (전처리 작업)
사실 제일 어렵고 오래걸리는 것 ....
-> 현업에서는 데이터자체에 노이즈가 많고 이상치 값들이 많다.
전처리 작업을 잘한다 = 데이터 성능이 좋다 라고 생각해도 될 정도라고 한다!
1. Bounding box

2. Resize
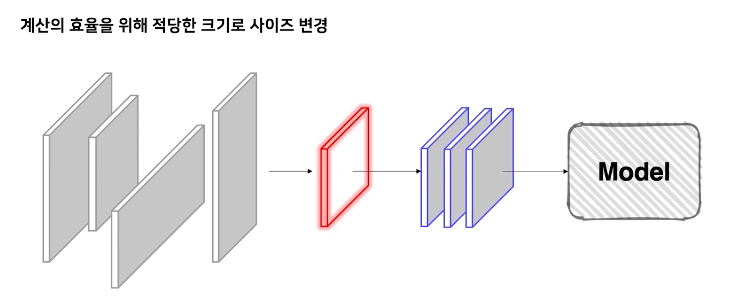
-> 빠르게 학습을하고 결과를 보기 위해서 size을 모델에 맞춰 효율적으로 크기 조절을 하는 것이 좋다.
그렇다면 이미지데이터에서 전처리방식은 어떤 것이 있을까?
어떠한 특수한 도메인에서 특수한 전처리가 중요할 때가 많다
예를들어서
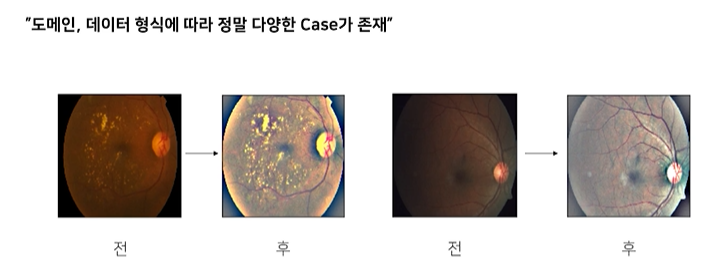
이러한 medical 이미지 데이터에서는 어두워서 잘 보이지 않는 부분을 밝게 만들어 잘 보이도록 전처리하는 것이
모델학습에 도움이 된다.
그렇다고 무조건 전처리를 해야 학습에 도움이 된다 (X) ->사실 실험을 통해 알 수 있다.
Generalizastion( 일반화)
-학습된 데이터 뿐 아니라 Test Data에서도 성능이 좋게 하는 것
즉 다른 외부 Data을 넣어도 Training Data로 모델을 학습한 것과 거의 비슷한 결과를 얻는 것을 말한다.
만약 일반화가 되지 않았을 때는 ?
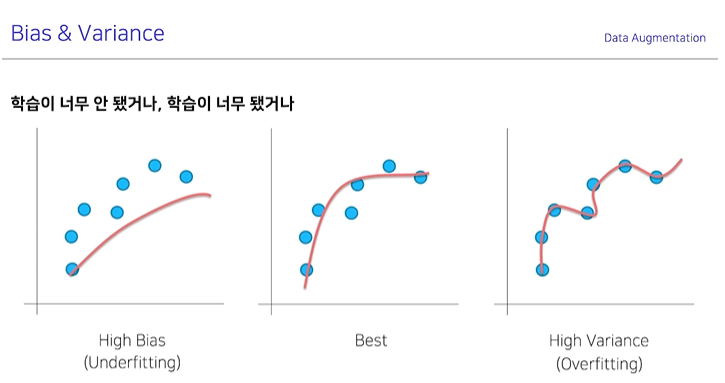
High Variance (Overfitting) : 데이터가 너무 학습데이터에 치중되어 (학습이 너무 됐을 때) Test Data(학습하지 않은 Data)에서는
성능이 좋지않은 현상
High Bias (Underfitting) : Overfitting과 반대로 데이터가 충분히 모델에 학습되지 않은 현상
-> 이 두 현상의 중간에 도달하는 것이 최적화된 모델이라고 볼 수 있다.
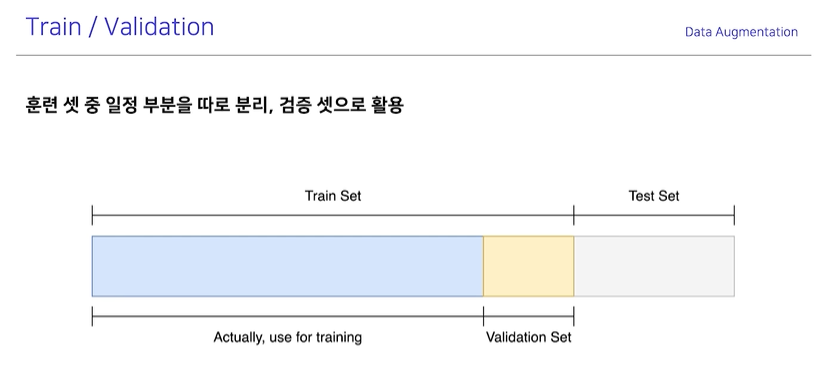
검증 set을 넣는 이유: Training하며 일반화가 잘 되고있는지 Checking하기 위해서
-> 만일 중간에 Validation의 성능이 좋지않다면 중간에 멈추며 시간을 효율성있게 쓸 수 있다.

주어진 데이터에대해서 어떠한 현상이 생길 지 위에 그림처럼 예상할 수 있다.
그렇기 때문에 데이터가 가질 수 있는 현상의 다양성을 적용해 어떠한 input Data가 들어왔을 때
좀 더 정확성이 높아진다.-> 일반화 과정에도 도움이 된다.
★ 문제가 만들어진 배경과 모델의 쓰임새를 살펴보면 힌트를 얻을 수 있다
Competition의 마스크적용을 생각해본다면?

하지만 마스크착용여부를 알아볼 때 사실 뒤집힌 사진처럼 Input Data가 들어오기는 힘들기 때문에
사실 Flip사진으로 Training하는 것은 무의미하다
->그렇기 때문에 어떠한 데이터가 주어졌을 때 도메인을 이해하는 것은 중요!
쓰이는 함수>torchvision.transforms
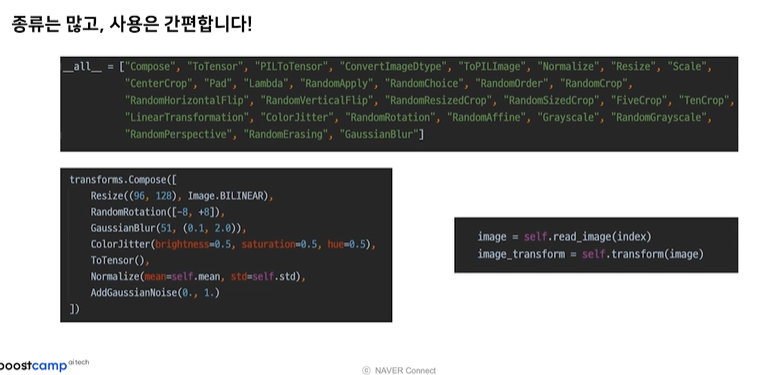
+Albumentations

하지만 중요한 것!
항상 좋은 결과는 가져다 주지는 않는다.
이러한 함수들은 여러가지 도구 가운데 하나일 뿐, 무조건 적용 가능한 마스터키 같은 것도 없다.
앞서 정의한 Problem을 깊이 관찰해서 어떤 기법을 적용하면 다양성을 가질 수 있겠다 가정하고
실험으로 증명해야 한다!
Data Generation
이전은 데이터셋을 구성하는 방식이었고 Data Generation은 데이터를 잘 표현해주는 것!
그렇다면 어떻게 데이터를 잘 뽑아낼 수 있을까?
Data Feeding
->" 데이터에 먹이를 주다" 처럼 생각하며 이해해보자!
"먹이를 주다" = 대상의 상태를 고려해서 적정한 양을 준다.

모델의 처리량만큼 Data을 Generating할 수 있냐가 여기서의 제일 중요한 부분이다.
Model의 성능과 Generator의 성능의 차이가 있다면 효율성이 낮아지는 결과가 도출된다.
그래서 모델학습을 진행할 때, 데이터를 만들어내는 Generator가 성능이 어느 정도인지 초당 Batch가 얼마나 나오는지
꼭 확인해 볼 것!!!!!
효율성을 위해서 이러한 engineering적인 부분도 꼭 숙지하는 것이 좋다 !
한번 예시를 보자
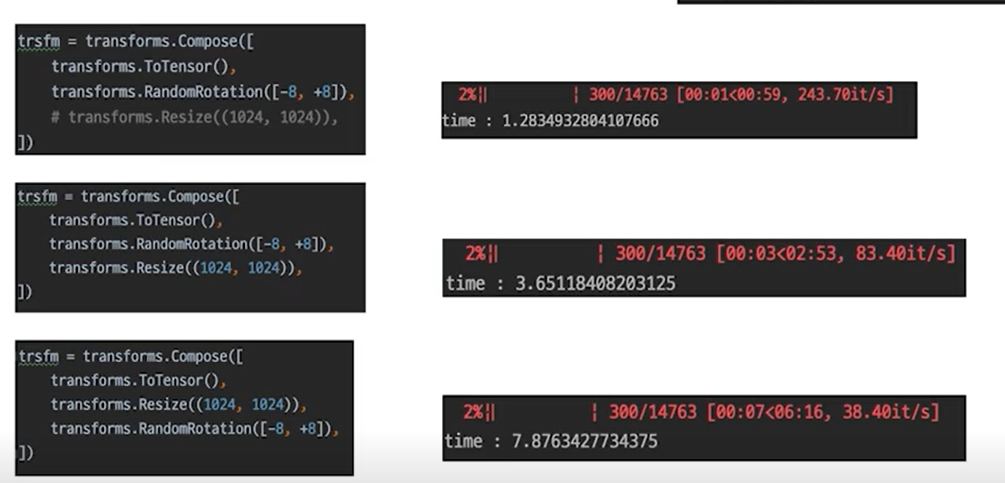
이렇게 Data을 구성하는 부분에서도 Resize의 유무와 순서로도 성능의 차이가 눈에띄게 달라지는 것을 볼 수 있다.
그렇기 때문에 데이터를 구성하는 부분에서도 여러 실험이 필요하다.
2021-08-24 회고 + Competition
오늘 데이터 라벨링을 구성했다.
그치만 데이터라벨링 나에게 너무너무 오래걸렸다.. 결과 값에 맞춰 18개로 나눠 라벨링하는데 뭔가 처음에는 쉬울 것 같았지만 여러 라이브러리를 사용하고 그러는게 너무 익숙하지 않아 시간이 꽤 오래 걸렸던 것 같다 ..ㅠㅠ
그러고 나서 EDA파일이 공유되어 프로그래밍해보는데 내가 너무 단순하게 데이터를 본 것 같기도하고
갑자기 머리가 더 복잡해져서 오후를 거의 데이터 분석하는데만 쓴 것 같다..
특히 Competition에서 제공된 데이터를 보며 EDA을 해보는데 굉장히 난 어려웠던 것 같다 ..ㅠㅠ
EDA을 실행해보면서 느낀건 성별이 남자인 데이터의 비율이 상대적으로 성별이 여자인 데이터보다 꽤 높았는데
그 부분에서 성별이 여자인 데이터를 늘려준다라던가 , 아니면 나이대에 따른 데이터의 양의 차이도 확인할 수 있었고,
그리고 class에서 나이의 경계선에 있는 데이터의 분류도 어려움이 있을 것 같다라는 생각도 들었다
그리고! 오늘 멘토님과 이 부분에 대해 이야기해보았는데 하나의 모델을 만들어 18개 class을 도출하도록 하는 방법도 있지만 나이별 / 성별 / 마스크의 착용 유무 이렇게 3가지 모델을 만들어 연결지어 클래스 분류하는 방법도
좋은 방법이라고 한다.! 그치만 나에겐 아직 감이 오지않는 것 같다..
일단 내가 가장 먼저할 일은 내일 정확도를 체크해보고 EDA에 대해서 더 생각해보는게 순서가 맞다고 생각해
얼른 파이프라인을 만들러 가야겠다..!!!!
내일 꼭 정확도가 낮더라도 나왔으면 하는 나의 바람 :-)
읽어주셔서 감사합니다!!!
'BOOST CAMP_정리' 카테고리의 다른 글
| [Boost Camp] Week 4 Day 4 P.stage (Training and Inference)+회고 (0) | 2021.08.27 |
|---|---|
| [Boost Camp] P.stage (Model) (0) | 2021.08.26 |
| [Boost Camp] WEEK 4 Day 1. P stage(EDA) (0) | 2021.08.23 |
| [Boost Camp] 2주차 회고록 (5) | 2021.08.17 |
| [Boost Camp] WEEK 2.Day4 RNN과 LSTM (0) | 2021.08.16 |


