
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 카카오 파이썬
- 부캠
- docker시작하기
- 카카오코테
- 파이썬 프로그래머스
- 프로그래머스 레벨1
- 라이브러리란?
- 파이썬 양과늑대
- 프로그래머스 양과늑대
- 프로그래머스 레벨2
- 부스트캠프
- 프로그래머스
- 파이썬
- 부스트캠프AITech
- 도커오류
- 도커연결오류
- 프로그래머스 파이썬
- Cannot connect to the Docker daemon at unix
- 양과늑대
- 코딩테스트
- 프로그래머스 레벨3
- 카카오코딩테스트
- 카카오 코딩테스트
- 파이썬 카카오코딩테스트
- 네이버 부스트캠프
- 부스트캠프 회고
- 파이썬 재귀함수
- 프레임워크란?
- 프로그래머스LEVEL1
- level1
- Today
- Total
코린이의 공부일기
[Boost Camp] U stage_ Conditional generative model 본문
오늘 포스팅은 길 예정 !
Conditional generative model

서로 다른 두메인을 translation 하는 것
"sketch of a bag" -> condition(조건)
이 주어진 상태에서 결과가 도출되는 것
즉 조건이 주어진 상태에서 X(이미지)가 나올 확률
Generative model vs Condtional Generative model

기본적인 generative model에서는 조작이 불가능하고 Random 하게 생성만 가능하다.
Conditional generative model은 주어진 조건에서 생성이 가능하다.
기존 generative adversarial model 구조

Z -> random noise( latent vector)
Generator -> 위조지폐범이라 생각 즉 위조지폐를 경찰이 잘 알아차리지 못하도록 최대한 실제지폐와 근사하게 만듬
Discriminator-> 경찰이라 생각 즉 위조지폐를 실제지폐와 근사하게 만들더라도 가짜로 구별할 수 있도록 구별능력훈련
Fake ? Real ?(0~1사이의 수치) 의 값으로 우리의 목적은 최대한 확률 값이 1에 가깝게(진짜로 인식) 하도록 하는 것이 목적이다
이렇게 Generator와 Discriminator의 적대적 학습법을 사용한다.
그렇다면 GAN과 Condition GAN의 구조는 어떻게 다를까?

*Conditional GAN 은 GAN의 구조전체를 다 갖고오돼 Generator input 값에 Condition을 추가하여
내가 원하는 조건의 데이터를 생성할 수 있다.
Conditional GAN의 응용사례는 무엇이 있을까?

원래의 이미지에서 스타일을 바꾸는 방식, 저해상도에서 고해상도 바꾸는 방식, 흑백사진에서 컬러사진으로 바꾸는 방식 등 많은 응용사례가 있다. 또한 게임에서는 제작비용없이 전혀다른 게임테마를 만들 수 있다.
좀 더 GAN에 대해 자세하게 살펴보자면,

만일 색상 검정색과 흰색을 Real Image 로 두고 L1 loss을 쓰고 Regression모델로 학습을 한다면 일반적인 회색이 나온다. 왜냐하면 흰색과 검정색 둘중 하나에 편향된다면 한쪽에서 Error값이 크게 나오기 때문에 가장 적절한 error값이 나오도록 하는 회색이미지를 도출한다.
But GAN모델은 Discriminator(판별자)을 사용한다. 그래서 판별자는 회색이미지는 진짜(1에 가까운값) 으로 판별하지 않기 때문에 검정 /흰색을 도출한다.
Pix2Pix (2017)
도메인 간의 변화의 문제를 다룬 논문으로 image to image translation으로 처음 정의한 논문이다.

그렇다면 Pix2Pix의 Loss function을 무엇일까?

Pix 2 pix Loss function은 GAN loss와 MAE loss을 합친형태이다.
불안정한 GAN의 Lossfunction에 L1 norm을 추가해 안정적으로 training 하기위해 guide을 제공했다.
그렇다면 Un pairwise dataset에서는 어떠한 방식을 실행할까?

바로 Cycle GAN !
그러면 Cycle GAN이란 무엇일까?

domian간에 직접적 1:1 관계가 아닌 non pair-wise data로 훈련하는 모델이다.
-> 1:1관계는 굉장히 제한적범위에 적용할 수 있는 단점이 있는데 이를 보완하여 응용 범위가 늘어나는 장점이 있다.
CycleGAN Loss function

GAN loss와 Cyle-consistency loss을 합친 형태이며
GAN loss로 X-> Y로 가는 방향과 Y->X로 가는 방향을 동시에 같이 학습을 진행하는 특징이 있다.
1. Cycle Loss_ GAN loss function

X Data에서 G을 통해 Y Data가 나오고 Real Y Data와 Discriminator을 통해 판별하며
Y Data에서 F을 통해 X data가 나오고 Real X data와 Discriminator을 통해 판별한다.
-> 각각 다른 Discriminator로 구별
G,F - Generator(생성자)
Dx,Dy - Discriminator(판별자)
But GAN loss만 사용한다면 문제점이 생긴다 -> Mode collapse 현상
그렇다면 Mode collapse 현상은 무엇일까 ?

어떠한 Input값이든 항상 똑같은 output값을 도출하는 현상이다.
Solution : Cycle-consistency loss를 사용해 style뿐만 아니라 contents도 유지

Contents을 보완하기 위해서 Cycle-consistenct loss을 추가한다.
Cycle-consistency는 X에서 Y로 변환되었다가 다시 X로 변환하는 방식
But 처음 x와 도출된 x의 차이가 있으면 안된다!
내부의 content유지를 위해 Dx,Dy 둘 다 적용하며 입력된 X와 도출된 X사이의 거리를 loss값으로 두고 둘 간의 차이를 최소화 시킨다.
+
GAN은 굉장히 학습하는데에 오랜 시간이 걸린다
Generator는 Minimize하고 반대로 Discriminator는 Maximize을 하며 서로 반대의 상황을 가지고
Generator -> Discriminator 서로 한번 씩 돌아가며 반복적으로 진행하기 때문이다.
그렇기 때문에 ! 이 GAN Loss을 보안한 Loss가 바로 Perceptual Loss 이다.
Perceptual Loss
일반적인 neural network와 같이 forward와 backward로 구성되어있으며 GAN Loss 처럼 서로 바꾸면서 진행하는 Alterative training하지 않는다.
But Pretrained model을 사용해야한다.

1.input image(x)을 image transform Net에 넣고 생성된 예측 값을 나오게한다.
2. 생성된 예측값을 Pretrained model(VGG) 에 넣어 중간중간 activation을 뽑아준다.
3. style target와 Contect Target으로 Loss값을 지정해준다.
* 주의 - VGG는 Fix 된 상태이고 결과 값에 따라서 Image Transform Net이 업데이트 되는 방식이다.
조금 더 자세하게 설명하자면!
1. Feature reconstruction loss
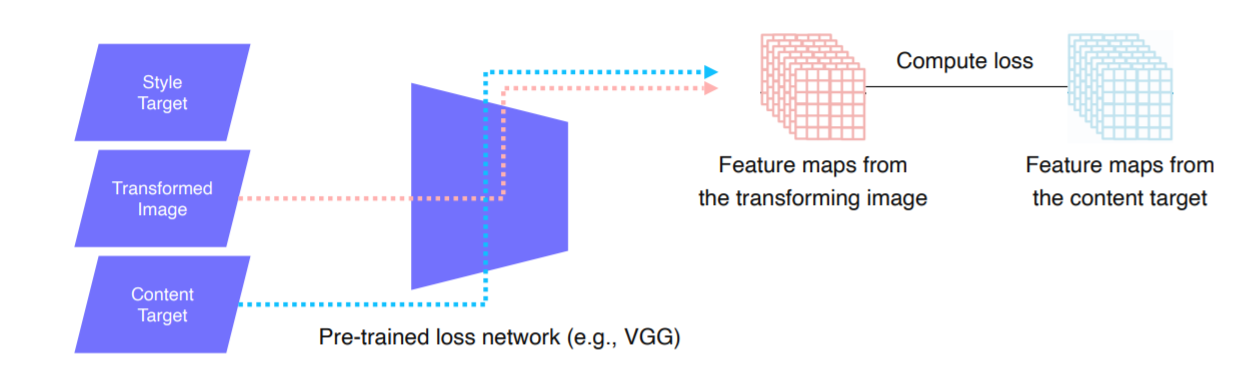
- Input을 Transform net에 넣어서 나오는 예측 값이 우리가 원하는 값으로 나오기 위해 Content 을 잘 유지하도록 도와주는 loss가 Feature reconstruction loss이다.
-원래 원초적인 X값을 Contect Target입력 값으로 넣어 나온 값을 다시 VGG에 넣어 나오는 Feature(오른 쪽 값) 그리고
Transformed image을 VGG에 넣어 생성된 Feature
이 두 개를 비교해 Compute loss을 진행한다.(비슷한지 )
여기서 Loss는 L2 loss을 사용한다.
2.Style reconstruction loss

-Feature constructio loss와 구조가 거의 동일하지만 Feature map에서 loss을 바로 계산하지 않고 style을 추출하기 위해 Gram matrices을 사용한다.
- 우리가 변환하고 싶어하는 스타일(ex_ 반고흐스타일의 이미지)와 같은 내가 원하는 스타일을 Style Target으로 둔다.
그래서 위와 마찬가지로 Style target에서 나온 Feature와 Transformed image나온 Feature 들을(3DTensor형태의 Feature maps) 위에처럼 바로 비교하지않고 Gram matrices(통계적 특성을 가진 행렬)로 변환(channelXchannel)하여
Loss을 구한다.(정해준 스타일을 따라가도록)
Gram matrix 구하는 방식
c*(h*w) reshape(2D) -> c*(h*w) X (h*w)*c 계산 -> c*c Gram matrix
각 채널 끼리 내적값(채널 간의 관계) 가 matrix에 들어간다.-> 유사도를 평가
즉 쉽게 말하면 패턴들 간의 경향성을 비교 !!!
* 교수님이 Gram matrix을 꼭 찾아보길 권장하셨다
Various GAN applications
EX> DeepFake,Face-de-identification, Video translation
+
내가 가장 관심있는 분야 중 하나인 GAN을 더 보고싶어 GAN의 오리지널 논문
https://arxiv.org/abs/1406.2661에서 중요한 수식부분만 가져와 정리를 해보았다. 포스팅예정 😀
gan논문에 대해 자세히 써있는걸 서치하는데 최대한 자세하고 깔끔하게 써주신 블로그를 찾았다. 많은 gan의 응용한 모델의 정리도 있으니 꼭 보길 추천 드립니다 : )
참고 >http://jaejunyoo.blogspot.com/2017/01/generative-adversarial-nets-1.html
초짜 대학원생 입장에서 이해하는 Generative Adversarial Nets (1)
쉽게 풀어 설명하는 Generative Adversarial Nets (GAN)
jaejunyoo.blogspot.com
2021_09_15_ 회고
오늘은 엄청나게 어려운 부분이였다^^,,, 오리지널 GAN을 이해하는데에도 꽤나 오랜시간이 걸렸는데 Conditional GAN은 사실 더욱 오랜 시간이 걸릴 예정이다...^^
오늘 팀원들과 오리지널 GAN에 대해서 서로 이야기하고 공유했는데 기본 GAN구조를 이해하는데에 많은 도움이 된 것 같다 : )!
그치만 아직 latent vector가 상황에 따라 어떻게 정해야할지 그것도 너무 의문긴하다,,!
random noise 라고 하긴하는데 이건 엄청 간단한 gan을 이용할 때 쓰이는 것 같은데..! 흠 더 찾아봐야겠다.
그리고 오늘 팀원분께서
input data을 image로 Condition을 음성으로주고 Conditional GAN을 진행했을 때, 음성에 따라 image가 변하는 프로젝트를 진행하신걸 보여주셨다.
불소리를 Condition으로 주니 이미지에 불이 생기는 걸 보여주셨는데 너무너무신기했다!!!
사실 나는 GAN이 이미지나 영상에만 아니면 음성에서만 사용할 수 있는줄 알았는데 여러 도메인에서도 서로 상호작용해 사용할 수 있다는 너무 큰 배움을 얻었다.!!
그리고 팀원분께서 Diffusion Model도 꼭 찾아서 보라고 알려주셨는데 , 한번 찾아서 공부해봐야겠다 : )
팀원 분 체고 !!!

'BOOST CAMP_정리' 카테고리의 다른 글
| [Boost Camp] 09_24 특강 (0) | 2021.09.24 |
|---|---|
| [Boost camp] 09_23 특강 (0) | 2021.09.23 |
| [Boost Camp] U.stage_Object detection (0) | 2021.09.12 |
| [Boost Camp] U.stage_Semantic Segmentation (0) | 2021.09.09 |
| [Boost Camp]U stage_CNN (0) | 2021.09.06 |



