
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 카카오 파이썬
- 카카오코테
- 파이썬 프로그래머스
- 카카오 코딩테스트
- 도커연결오류
- 프로그래머스 레벨1
- 네이버 부스트캠프
- 카카오코딩테스트
- 부스트캠프
- 프로그래머스 레벨3
- 양과늑대
- 프레임워크란?
- 프로그래머스
- 부스트캠프 회고
- 라이브러리란?
- 파이썬 재귀함수
- 파이썬 카카오코딩테스트
- 프로그래머스 양과늑대
- 파이썬 양과늑대
- 부스트캠프AITech
- 프로그래머스LEVEL1
- docker시작하기
- 부캠
- 코딩테스트
- 프로그래머스 파이썬
- level1
- 프로그래머스 레벨2
- 파이썬
- 도커오류
- Cannot connect to the Docker daemon at unix
- Today
- Total
코린이의 공부일기
MLOps 본문
모델 개발 프로세스 - Production
웹, 앱 서비스에서 활용할 수 있게 만드는 과정
-"모델에게 데이터(input)을 제공하면서 , output 예측해주세요" 라고 요청하는 과정
MLOps란?
-머신러닝 모델을 운영하면서 반복적으로 필요한 업무를 자동화시키는 과정
= 머신러닝 엔지니어링 + 데이터 엔지니어링 + 클라우드 +인프라
즉 머신러닝 모델 개발과 (ML Dev)과 머신러닝 모델 운영(Ops)에서 사용되는 문제, 반복을 최소화하고 비즈니스 가치를 창출하는 것이 목표!
-> 모델링에 집중할 ㅅ 있도록 관련된 인프라를 만ㅇ들고, 자동으로 운영되도록 하는 것
게다가 최근에는 비즈니스 문제에는 머신러닝/딥러닝을 적용하는 Case가 많아짐
특히 현실에서는 예측할 수 없는 리스크가 굉장히 많기 때문에 Production 환경에 배포하는 과정엔 Research의 모델이 재현가능해야 한다.
즉 MLOps의 목표는 빠른 시간 내에 가장 적은 위험을 부담하며 아이디어 단계부터 Production 단계까지 ML 프로젝트를 진행할 수 있도록 기술적 마찰을 줄이는 것
MLOps Component -Serving library
시간 순에 따른 Star개수

MLOps Component - Experiment, Model Management
auto log을 통해 모델의 학습한 결과와 파라미터 값과 실험자가 다 나온다.


* 과제
1.MLOps가 필요한 이유 이해하기
Au
2. MLOps의 각 Component에 대해 이해하기(왜 이런 Component가 생겼는가?)
3. MLOps 관련된 자료, 논문 읽어보며 강의 내용 외에 어떤 부분이 있는지 파악해보기
4. MLOps Component 중 내가 매력적으로 생각하는 TOP3을 정해보고 왜 그렇게 생각해는지 작성해보기
-> 자신만의 언어로 노션, 블로그에정리
Product serving
1. Online Serving
2.Batch Serving
Web sever- Client의 다양한 요청을 처리해주는 역할
(주문받기, 신규고객응대, 계산과 같은 예시로 들어서 생각할 수 있다.)
Machine Learning Serve는 데이터 전처리, 모델을 기반으로 예측 등

API( Application Programming interface)
운영체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스
Ex) 특정 서비스에서 해당 기능을 사용할 수 있도록 외부에 노출 : 기상청 API, 지도 API
라이브러리의 함수 : Pandas, Tnesorflow, Pytorch
Online Serving Basic
-요청(request)이 올 때마다 실시간으로 예측
-클라이언트(에플리케이션)에서 ML모델 서버에 HTTP요청 (request)하고,
머신러닝 모델 서버에서 예측한 후, 예측 값(응답)을 반환(Response)
Serving input -Single Data Point
단일 데이터를 받아 실시간으로 예측을 하는 예제
Online Seving Basic
-1) 직접 API 웹 서버 개발 : Flask, FastAPI 등을 사용해 서버 구축
-2) 클라우드 서비스 활용: AWS의 SageMaker, GCP의 Vertex AI 등
-3) Serving 라이브러리 활용 : Tnesorflow Serving, Torch Serve, MLFlow, BentoML 등

* 다양한 Seving 방법을 선택하는 가이드
추천방식 (만약 회사에서 클라우드 비용에 대해 괜찮을 경우)
1) 프로토타입 모델을 클라우드 서비스를 활용해 배포
2) 직접 FastAPI 등을 활용해 서버 개발
3) Serving 라이브러리를 활용해 개발
이런 Flow을 체험하는 것을 추천!
Online Serving에서 고려할 부분
1) Input 데이터를 기반으로 Database에 있는 데이터를 추출해서 모델 예측해야 하는 경우
-데이터는 다양한 공간에(Database)에 제장되어 있을 수 있음
-데이터를 추출하기 위해 쿼리를 실행하고, 결과를 받2)는 시간이 소요
2) 모델이 수행하는 연산
-RNN, LSTM등은 회귀 분석보다 많은 연산을 요구하고 더 오래걸린다.
이를 통해 모델을 경량화하는 작업이 필요할 수 있다.
3) 결과 값에 대한 보정이 필요한 경우
머신러닝 알고리즘에서 유효하지 않은 예측값이 반환될 수 잇음
-데이터의 후처리가 필요할 수 있다.
Batch serving
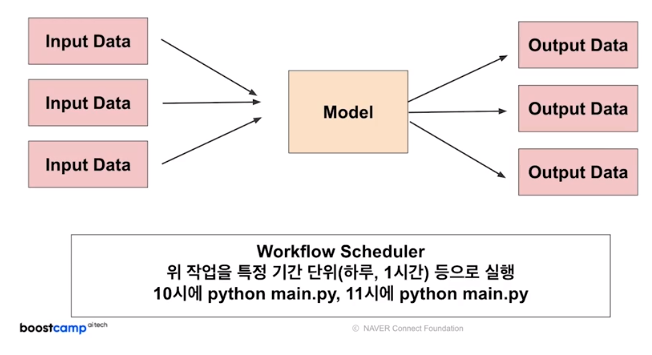
Batch Serving Basic
Batch Serving은 주기적으로 학습을 하거나 예측을 하는경우
-30분에 1번씩 최근 데이터를 갖고 예측
-Batch 묶음(30분의 데이터)을 한번에 예측
-모델의 활용 방식에 따라 30분일 수도 있거, 1주일, 하루 단위 일 수 있음
-한번에 많은 예측을 실행
-> 학습 과 예측을 분리해 실행할 수 있다.
예를들어 추천시스템: 1일 전에 생성된 컨텐츠에 대한 추천 리스트 예측
1시간뒤 수요 예측
재고 및 입고 최적화를 위해 매일 매장별 제품 수요 예측
실시간이 필요없는 대부분의 방식에서 활용이 가능하다.
->장점은 주피터노트북으로 작성한 코드를 함수화한 후, 주기적으로 실행하는 간단한 구조!
온라인 서빙보다 구현이 수월하며 많은 양의 데아터를 처리하므로 Latency 가 문제되지 않음
-> 대신에 실시간 추론은 불가능
Online Serving vs Batch Serving
Online vs batch 를 선택하는 기준 -input관점
데이터 하나씩 요청하는 경우 : online
여러가지 데이터가 한꺼번에 처리되는 경우 : batch
서버와 통신이 필요한 경우 -Online
1시간에 1번씩 예측해도 괜찮으 경우 -Batch
실시간 모델 결과가 어떻게 활용되는지에 대한 생각이 필요!
Batch Serving의 결과를 Database에 저장하고, 서버는 Database의 데이터를 쿼리해서 주기적으로 조회하는 방식으로 사용할 수 있음.
우선 Batch Serving으로 모델을 운영하면ㅅ 점점 API형태로 변환
https://developers.google.com/machine-learning/guides/rules-of-ml
Rules of Machine Learning: | ML Universal Guides | Google Developers
Send feedback Rules of Machine Learning: Best Practices for ML Engineering Martin Zinkevich This document is intended to help those with a basic knowledge of machine learning get the benefit of Google's best practices in machine learning. It presents a sty
developers.google.com
문서 읽고 정리하기 !
Online Serving/Batch Serving 기업들의 Use Case찾아서 정리하기(어떤 방식으로 되어있는지 이해가 되지 않아도 문서를 천천ㅊ히 읽고 정리하기)
'BOOST CAMP_정리' 카테고리의 다른 글
| AutoML의 이론 (0) | 2021.11.23 |
|---|---|
| [Boost Camp] 7강 _ 성능 평가 방식 (0) | 2021.11.11 |
| semantic segmentation 대회에서 사용하는 방법 (0) | 2021.10.26 |
| [Boost Camp]MMDetection & Detectron2 (0) | 2021.09.29 |
| [Boost camp] 2 Stage Detectors (0) | 2021.09.28 |



